
Materials Informatics and Data Mining for Materials Science
September 24, 2008
Krishna Rajan
Broadly speaking, two primary functions of data mining--pattern recognition and prediction---together form the foundations for the study of material behavior and for material discovery. The search for new or alternative materials, for instance, whether through experiment or simulation, is a slow and arduous process, punctuated by infrequent and often unexpected discoveries. Each such finding prompts a flurry of studies in which we seek to better understand the science governing the behavior of the new material. While informatics is well established in some fields--such as biology, drug discovery, astronomy, and quantitative social sciences--materials informatics is still in its infancy. Results of the few systematic efforts undertaken to analyze trends in data as a basis for predictions have been in large part inconclusive, not least because of the lack of large amounts of organized data and, even more important, the challenge of sifting through the data in a timely and efficient manner.
It might seem natural to assume that large amounts of data are critical for any serious informatics study. In materials science applications, however, what constitutes "enough" data can vary significantly. In structural ceramics, for instance, it is difficult to obtain measurements of "fracture toughness," and, in fact, just a few careful measurements can be of great value for some of the more complex materials. Similarly, reliable measurements of fundamental constants or properties for a given material require the use of very detailed measurement and/or computational techniques. Unlike astronomers or biologists, who look at the world (environment) around them to gather data and then analyze it to find out what is important, materials scientists do a great deal of analysis (and/or experimentation) to get their data. The result is a number of challenges that are unique to materials science: lack of sufficient data, skewed datasets, and missing information, among others. On the other hand, the emergence of high-throughput data-acquisition techniques in materials science, such as combinatorial experimentation, offers unprecedented opportunities as well as challenges in data-driven discovery techniques [1]. With such widely different issues in data characteristics, materials science offers an exciting domain for the application of the science of data mining.
Examples of Materials Informatics: Solving Materials Science Questions with a Data Mining Paradigm
Data mining and clustering analysis of very large datasets. Atom-probe tomography is a powerful type of microscopy that allows spatial (sub-nanoscale) resolution of hundreds of millions of atoms in a single experiment, so that their chemical identities can be determined via time-of-flight mass spectroscopy. The three-dimensional reconstruction of this direct space information provides unprecedented capabilities for characterizing materials at the atomic level. We have developed parallel computational methods based on autocorrelation, a powerful multivariate statistics tool [2]. Our method unravels atomistic-scale clustering in three dimensions from atom-probe data, and can easily scale to a billion atoms. Using it, we can directly and quantitatively track temporal changes in chemical clustering associated with nucleation and growth of nanoscale precipitates in multicomponent alloys. The output of the study was the development of density correlation functions that map how different elements in the alloy cluster in three dimensions, leading to the formation of nanoscale precipitates. (See Figure 1.)
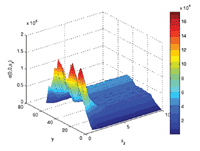
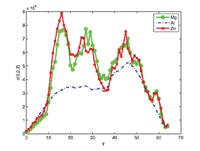
Figure 1. Left, one-dimensional autocorrelation along the y-axis for Mg atoms in an Al�1.9Zn�1.7Mg alloy at t=3600 sec. Right, a cross section showing the superimposition of Mg, Al, and Zn autocorrelation functions. The co-clustering of Mg and Zn is clearly visible. From [2].
Data mining for combinatorial catalysis experiments. We examined a dataset of 1001 catalyst chemistries, sampling the complete composition spread of a five-dimensional search space containing the elements Cr, Co, Mn, Mo, and Ni. We applied principal component analysis to the dataset in order to detect correlations between involved elements and selectivity or activity, respectively. By using singular value decomposition techniques to reduce data dimensionality, combined with clustering analysis, we established correlations between the presence of a specific metal species and the selectivity of a given reaction product. In this manner, we have been able to identify which combinations of constituents of heterogeneous catalysts are related to which final products from a large combinatorially generated dataset.
Data Mining Challenges
Materials informatics is pervasive, with roles to play in all areas and applications of materials science. It can influence the way we do experiments and analyze data, and could even alter the way we teach materials science. Ultimately, the "processing�structure�properties" paradigm that forms the core of material development is based on an understanding of multivariate correlations and their interpretation in terms of the fundamental physics, chemistry, and engineering of materials. The field of materials informatics can advance that paradigm in a significant manner. A few critical issues are central to efforts now under way to build the informatics infrastructure for materials science:
1. How can data mining/machine learning be used most effectively to discover the attributes (or combinations of attributes) that govern specific properties in a material? Using information from different databases, we can compare and search for associations and patterns that could lead to ways of relating information among the different datasets.
2. What are the most interesting patterns that can be extracted from existing materials science data? Such a pattern search process can potentially yield associations between seemingly disparate datasets and could also establish possible correlations between parameters that are not easily studied experimentally in a coupled manner.
3. How can we use associations mined from large volumes of data to guide future experiments and simulations? How can we select from a materials library the compounds that are most likely to have desired properties? Incorporation of data mining methods into design and testing methodologies would increase the efficiency of optimizing materials processing techniques. For instance, a possible testbed for material discovery can involve the use of massive databases on crystal structure, electronic structure, and thermochemistry. Each of these databases by itself can provide information on hundreds of binary, ternary, and multicomponent systems. This library, coupled with electronic structure and thermochemical calculations, can be enlarged to permit a wide array of simulations for thousands of combinations of material chemistries. Such a massively parallel approach to the generation of new "virtual" data would be a daunting if not impossible task were it not for data mining tools.
In conclusion, data-intensive approaches to the discovery of behavioral models (as opposed to traditional mathematical modeling) can be powerful tools for accelerating progress in materials science.
References
[1] K. Rajan, Combinatorial materials science: Experimental strategies for accelerated knowledge discovery, Ann. Revs. Mater. Res., 38 (2008), to appear.
[2] S. Seal, K. Rajan, S. Aluru, M. Moody, A. Ceguerra, and S. Ringer, Tracking nanostructural evolution in alloys: Large-scale analysis of atom probe tomography data on Blue Gene/L, Proceedings of the 37th International Conference on Parallel Processing, in press, 2008.
[3] S.C. Sieg, C. Suh, T. Schmidt, M. Stukowski, K. Rajan, and W.F. Maier, Principal component analysis of catalytic functions in the composition space of heterogeneous catalysts, QSAR Comb. Sci., 26:4 (2007), 528�535.
Krishna Rajan holds the Stanley Chair of Interdisciplinary Engineering and is a professor of materials science and engineering at Iowa State University.
![]()
