
Mining the Sky: Data Analysis Meets Astronomy
April 3, 2002

Figure 1. FIRST data: Sample image maps and catalog entries for data collected from 1993 to 1999.
Chandrika Kamath
Data mining techniques are rapidly gaining acceptance in a variety of scientific disciplines as a viable approach to the analysis of large and complex data sets. This is especially true in astronomy, where the vast amounts of data collected in astronomical surveys require the use of semi-automated techniques for analysis [1]. Thus far, the focus has been on extracting interesting information from a single survey. With several surveys coming on-line, however, opportunities arise for mining data across several different surveys-allowing astronomers to exploit all the information available to them. In this article, I discuss the use of data mining techniques in astronomy, the issues associated with mining a single survey, and the challenges that lie ahead as these techniques are extended to the mining of data across several surveys.
Data mining is a process for uncovering patterns, associations, anomalies, and statistically significant structures in data. There have been several well-known applications of data mining in astronomy, both by astronomers using data mining techniques and by data miners working with astronomy data. Among them have been the use of neural networks to discriminate between stars and galaxies [5], as well as more recent efforts, such as the SKICAT project for star/galaxy classification using decision trees in the DPOSS survey [6], the JARTool project for the classification of volcanoes in Venusian imagery obtained from the Magellan spacecraft [2], and the identification of radio-emitting galaxies with a "bent-double" morphology in the FIRST survey as part of the Sapphire project [3]. All these efforts have focused on data from a single survey, although cross validation with other surveys is often done as part of the validation of the results obtained through data mining. The types of data have varied-radio-frequency in the FIRST survey, optical and near-infra-red in the DPOSS survey, and optical in the Magellan imagery of Venus.
Mining a Single Astronomical Survey
The data in an astronomical survey is often available in two forms---images and a catalog. The original data obtained by the telescopes, possibly after some preprocessing, is in the form of images, which, taken together, tile a large area of the sky (or astronomical object, in the case of Venus). Once the images are obtained, a catalog is created, providing information on each object in the image. It is the catalogs, not the images, that are the primary product of a survey.
A survey is defined by the wavelength of light used, the depth of the images, and the angular resolution of the images. For example, the FIRST survey (http://sundog.stsci.edu) is at radio frequency, with a wavelength of 20 cm, a resolution of 5.4 arc-seconds, and a flux density limit (depth) of 1 mJy (milli-Jansky). When complete, FIRST is scheduled to cover more than 10,000 square degrees of the northern and southern galactic caps. At a threshold of 1 mJy, there are approximately ninety radio-emitting galaxies and quasars in a typical square degree.
The classification of galaxies with a "bent-double" morphology in the FIRST survey is an example that illustrates the problems encountered in mining a single astronomical survey. Figure 1 shows an image map from the FIRST survey and the three catalog entries corresponding to one of the galaxies (a bent-double) in the image. These large image maps are mostly "empty," that is, composed of background noise that appears as streaks in the image.
The FIRST catalog [7] was obtained by processing an image map to fit two-dimensional elliptic Gaussians to each radio source. Each entry in the catalog corresponds to the information on a single Gaussian. This includes the coordinates RA (right ascension, analogous to longitude) and Dec (declination, analogous to latitude) for the center of the Gaussian, the major and minor axes, the peak flux, and the position angle of the major axis (degrees counterclockwise from north).
The FIRST survey, when complete, will contain almost a million galaxies and quasars. Relying on visual inspection of the images to find the objects of interest would therefore be infeasible. As a result, data mining techniques become invaluable for finding the useful information in this data.
The approach we took in classifying bent-double galaxies [3] was based on the catalog data, which was considered representative of many of the galaxies (all but the most complex). Because the catalog contains information on each Gaussian, with one or more Gaussians making up a galaxy, we first grouped the catalog entries. To do this, we had to choose a radius of interest within which the entries would form a galaxy.
We then focused on groups consisting of two or three catalog entries. This was based on the observation that a single-entry galaxy was unlikely to be a bent-double, while four or more entries in a galaxy would make it complex enough to be of interest to astronomers and therefore too complex for the easy application of data mining techniques. We extracted a separate set of features for the two- and the three-entry galaxies. We focused on such features as relative distances and angles between entries---features that were likely to be robust and invariant to rotation, scaling, and translation. Separating the two- and three-entry galaxies enabled us to have uniform-length feature vectors for each. We then applied dimension-reduction techniques from exploratory data analysis as well as principal-component analysis to identify the key discriminating features.
Next, working with a training set of bent-doubles and non-bent-doubles that had been manually identified by the astronomers, we created a decision tree classifier. We improved the classifier by refining the features until the desired accuracy was obtained. The classifier was then used to classify unlabeled galaxies.
Several issues encountered in our work on the FIRST survey illustrate the challenges of mining astronomy data. First, we observed that the pixel values in the images correspond to real physical quantities, such as radio intensities. This made it difficult for us to use traditional image processing software, which operates on gray-scale values. Several astronomical image processing systems available in the public domain can be used to address this issue, however.
Second, we found that in some images, very "bright" pixels could mask the true structure of the galaxy. Figure 2, for example, shows a galaxy obtained from the FIRST Web site with a maximum intensity for scaling of 10 mJy on the left and 80 mJy on the right. The brightest pixel in the image has a radio intensity of 609 mJy-bright enough to mask the true structure of the galaxy. In such cases, the image processing algorithms used to generate the catalog from the images might not be robust enough and can give catalog entries of poorer quality than the image.

Figure 2. A very bright galaxy (RA = 10 14 47.155, Dec = +23 01 15.57), seen with scaling of 10 mJy (left) and 80 mJy (right), revealing how very bright pixels can mask the true structure of a galaxy.
Third, grouping the catalog entries into galaxies was a nontrivial task. Because the images are really two-dimensional projections of objects in three-dimensional space, it is possible for two or more distinct galaxies to lie within the radius of interest, and therefore be counted as a single galaxy (see Figure 3). While the human visual system can easily identify the two galaxies, automated algorithms are incapable of such distinctions.
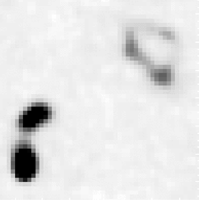
Figure 3. Two distinct galaxies are close enough to each other to appear as a single galaxy in the grouping of catalog entries (RA = 10 50 10.93, Dec = +30 39 46.60).
These observations indicate that while the original images are poor in predictable ways (e.g., due to the noise in the images), the postprocessing of the images into catalogs degrades the data further. Because the objects of interest are typically the rare ones, possibly lying outside the dynamic range of the instrument and thus appearing very bright or very faint, the data mining process needs to become more sophisticated, going back to the original images when it is clear that the catalog information is of poor quality.
Once the galaxies have been identified from the catalog, and the features representing them extracted in a robust way, additional issues must be addressed. If the problem is one of classification, a training set is needed with positive and negative examples (bent-doubles and non-bent-doubles in our case). Since the training set is identified manually, and the items of interest are often infrequent, the set is typically rather small (only 195 examples for three-entry galaxies in our case).
In addition, the objects of interest can be misclassified, due either to disagreement among the astronomers or to the drift associated with the visual labeling of objects by humans over a period of time [2, 3]. The misclassification tends to be more prevalent in the hard-to-classify cases, making the task of the classification algorithm even harder.
A possible solution to the problem of a small training set is to use clustering techniques to identify a possibly larger training set. A drawback of this approach, however, is that the clusters might not be cleanly separated and a galaxy might not have a unique class label associated with it. The number of objects may also make traditional clustering algorithms computationally expensive, and any sampling done to reduce this time may leave out the rare objects. Another solution is to begin by having the astronomers validate the labels assigned by the classifier, and then use the validated examples to enhance the training set. Of course, the results of these classification and clustering techniques are only as good as the features that are input to them.
Mining Across Several Astronomical Surveys
The challenges identified in the preceding section, with the classification of bent-double galaxies as an example, are only multiplied as we contemplate mining several astronomical surveys at the same time. This idea is likely to become reality in the near future as the astronomy community brings several surveys on-line as part of the National Virtual Observatory [4]. Included in this project are the FIRST survey, which is at radio frequency and is already on-line; the Sloan Digital Sky Survey (SDSS; http://www.sdss.org), in five optical colors, to be on-line shortly; the near-infra-red 2 Micron All Sky Survey (2MASS; http://www.ipac.caltech.edu/2mass/), which is on-line; the optical Guidestar catalog II (http://www-gsss.stsci.edu/gse/gsc2/GSC2home.htm); and others. Several earlier surveys, such as the Palomar Observatory Sky Survey (POSS), have also been digitized (DPOSS-Digitized POSS) and made available to the astronomy community. In these surveys, the raw image data is typically in gigabytes or terabytes, while the catalogs containing the information on millions or billions of objects are in megabytes or gigabytes.
Mining across several surveys is a very appealing idea in astronomy, as the complementary information in the different surveys can be used to break "degeneracies." Because a survey is conducted at a certain wavelength, depth, and angular resolution, a wide variety of the objects in it can have the same footprint, i.e., similar sets of features; this is a degeneracy.
To exploit multiple surveys, and their associated catalogs, we must first map an object in one survey to an object in another, thus creating a meta-catalog. This is typically done using the positional coordinates (RA and Dec), although this procedure, at best, yields only probable associations. However, the different resolutions of different surveys can cause two close objects in one survey to appear as a single object in another. To address this problem, the data mining software must be able to handle probabilities assigned to associations between objects. Each time a new survey is added, a different set of procedures will be needed to merge its catalog into the meta-catalog.
Once a meta-catalog has been created, an additional problem must be addressed before it can be mined. The sensitivities of the different surveys can cause an object that appears in one survey to fall below the sensitivity limits of another. An object could be bright in the 2MASS survey, for example, but faint in the SDSS. Thus, we need to find a way to represent the features for an object when it falls below the limits of a survey. Once this issue has been addressed, we can mine the meta-catalog, addressing the issues raised earlier for the mining of a single survey. These include going back to the original data when the catalogs have insufficient information, enhancing a small training set, and developing more robust and scalable algorithms for classification and clustering.
It is clear that challenges lie ahead, both in the mining of a single astronomical survey and in the mining of several surveys simultaneously. Any advances will require close collaborations with the astronomers, as well as a good understanding of the data and how it was collected and processed. These challenges can be viewed as opportunities for scientists in data mining, statistics, image processing, and mathematics, who can not only help advance the field of data analysis, but also contribute to our understanding of the universe by finding new science in this data.
Further Reading
For the reader interested in obtaining more information about data mining in astronomy and the sciences, the recent program on scientific data mining at the Institute for Pure and Applied Mathematics (IPAM) at UCLA (http://www.ipam.ucla.edu/programs/sdm2002) and the series of workshops on the same subject (http://www.ahpcrc.umn.edu/conferences) will be of interest. An edited book containing the papers from the first two workshops, titled Data Mining for Scientific and Engineering Applications, was recently published by Kluwer.
Acknowledgments
I would like to thank Bob Becker, the PI for the FIRST project, as well as his team, for our collaboration on the bent-double problem and for introducing us to the wonderfully challenging data mining problems in astronomy.
UCRL-JC-147376 ext abs.---This work was performed under the auspices of the U.S. Department of Energy by University of California Lawrence Livermore National Laboratory under contract No. W-7405-Eng-48.
References
[1] R.J. Brunner, S.G. Djorgovski, T.A. Prince, and A.S. Szalay, Massive datasets in astronomy, in Handbook of Massive Datasets, J. Abello, P. Pardalos, and M. Resende, eds., Kluwer, Boston, 2001.
[2] M. Burl, L. Asker, P. Smyth, U. Fayyad, P. Perona, L. Crumpler, and J. Aubele, Learning to recognize volcanoes on Venus, Mach. Learning, 30 (1998), 165-195.
[3] C. Kamath, E. Cant�-Paz, I. Fodor, and N. Tang, Searching for bent-double galaxies in the FIRST survey, in Data Mining for Scientific and Engineering Applications, R. Grossman, C. Kamath, W. Kegelmeyer, V. Kumar, and R. Namburu, eds., Kluwer, Boston, 2001, 95-114.
[4] National Virtual Observatory, http://www.srl.caltech.edu/nvo.
[5] S. Odewahn, E. Stockwell, R. Penning-ton, R. Humphreys, and W. Zumach, Automated star/galaxy discrimination with neural networks, Astron. J., 103, 1 (1992), 318-331.
[6] N. Weir, U. Fayyad, and S. Djorgovski, Automated star/galaxy classification for digitized DPOSS-II, Astron. J., 109, 6 (1995), 2401-2414.
[7] R.L. White, R. Becker, D. Helfand, and M. Gregg, A catalog of 1.4 GHz radio sources from the FIRST survey, Astrophys. J. 475 (1997), 479.
Chandrika Kamath is a research scientist in the Center for Applied Scientific Computing at Lawrence Livermore National Laboratory. She is the organizer of a session, "Mining Large Data Sets," for the SIAM International Conference on Data Mining (Arlington, Virginia, April 11-13).
![]()
