
What�s the Weather Like Now?
December 21, 2008
Julie Rehmeyer
If you're frustrated when weather forecasts get it wrong, consider this: They're often more reliable than data from weather stations themselves. Paradoxically, though, without regular updates from just such data, weather models produce forecasts that are no better than those from the Farmers' Almanac. So a key step in making a good forecast is to figure out what the weather is now.
For decades, applied mathematicians have worked to bring the theoretically elegant Kalman filtering method to bear on this problem in meteorology. Technical challenges have arisen, though, because of particularities of weather. But a team of mathematicians and meteorologists from the University of Maryland and Arizona State University believe that they have met many of these challenges. In tests, they have shown that their Kalman filtering code improves the accuracy of forecasts in some areas by as much as 65%.
They have made their code, called the Local Ensemble Transform Kalman Filter (LETKF), publicly available. LETKF is easy to implement, requiring little manpower and reasonable computing time, and it can easily be adapted to run on parallel computers. The Brazilian government is now considering adopting it for its national weather forecasts.
"I think it's the way of the future," says meteorologist Eugenia Kalnay of the University of Maryland, a leader of the group. "I am totally convinced everyone will be doing it."
Models have to be corrected with new data because of the central challenge of meteorology: Weather is chaotic. Left undisturbed, the output of even the best model will get further and further from the real weather over time. So every six hours, forecasters update their models with data about the current weather, giving the models new initial conditions to work from. If there were a tidy grid of weather stations across the entire Earth and extending up into the atmosphere, each one measuring every property included in the models, the updating would be a trivial matter.
In real life, weather stations are rare in the middle of the ocean or in tropical jungles. Satellites help make up for the gaps but can't observe most weather phenomena directly. For example, they infer wind speed from cloud motion, which requires guessing the height of the clouds. And those guesses aren't always right.
Forecasters have another source of information about the state of the weather: the forecasts themselves. Most of the time, six-hour forecasts predict temperatures accurately within half a degree. The trick is to combine the data with the forecasts to estimate what the true state of the atmosphere is likely to be. The right balance between the data and the forecast depends on the level of certainty of each.
Kalman filtering is a beautiful way to figure out how much weight to give to the forecast and how much to give to the data. An ensemble Kalman filter takes into account the variable certainty of forecasts. When a strong cold front pushes through the eastern U.S. in September, for example, the odds are good that several days of clear weather will follow, making for a pretty certain forecast. But a forecast made as a hurricane is churning northward along the East Coast may not be worth much.
Currently used data assimilation techniques don't account for such differences in confidence. "The U.S. Weather Service supposes that the uncertainty in a forecast at a given place and time is about the same tomorrow as it is today," says Eric Kostelich, a member of the LETKF team at Arizona State University, "when in fact that's not necessarily true."
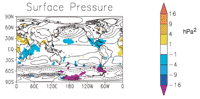
The LETKF team ran a "bake-off" between their model and the National Weather Service model. Because no one knows the exact state of the atmosphere, the team had to come up with some proxy for the truth. The "truth," the researchers decided, would be a high-resolution version of the National Weather Service model. This is the NWS's best estimate of the atmospheric state, combining the highest-resolution forecasts with all available observations. The team then compared this "truth" with the 48-hour forecasts generated by low-resolution versions of both the LETKF and the NWS models. LETKF predicted surface pressure more accurately in the areas shown in blue and purple, and less accurately in those shown in yellow.
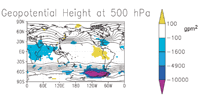
The topographical lines on this map show the heights at which the pressure of the air is 500 hectopascals. About half the atmosphere lies above this point, and about half lies below. In some areas of the southern hemisphere in which data is scarce, LETKF strongly outperforms the National Weather Service model. Maps from Eric Kostelich.
An ensemble Kalman filter quantifies the uncertainty by creating a collection of forecasts, not just one: Researchers run the model 50 times using slightly varying initial data. If those simulations lead to 50 very different results in one area, the re-searchers know that the forecast is highly uncertain there, and they rely heavily on the data from the weather stations. But in regions that come out pretty much the same, they trust the model's forecast more than the data.
Another advantage of running ensembles is a huge reduction in computational complexity. Traditional methods require full knowledge of the covariance matrix, which quantifies the correlations between any pair of weather data. The problem is that researchers don't know most of those correlations. Even if they did, the resulting matrix would be unmanageably huge. U.S. weather models use weather data on a 50-kilometer grid, with six pieces of data at each grid point. That produces about 75 million data points around the world. By the time the modelers included the covariances between the variables at each grid point, along with those between the variables at different gridpoints, their covariance matrix would have on the order of a billion by a billion entries. That's more than even a supercomputer could store, much less manipulate and invert.
The variability between the ensembles can serve as a substitute for the full matrix, reducing it to a mere 50 by 50. But there's a trade-off: Working with the matrix of ensembles instead of the full matrix reduces the information provided. The particular ensemble members chosen will not necessarily show the full variability possible. What Kalman filters do is balance greater precision in one area (by updating their measurement of the reliability of the forecasts) against less precision in another (the vastly reduced amount of detail about covariances). The details of the implementation determine whether the trade-offs are worth it, and many research groups have been working to strike the perfect balance.
The LETKF team thinks they've found it. They've tweaked the system in many subtle ways. For greater computational efficiency, for example, they consider only local effects, assuming that it will take more than the six hours since the last data update for the weather in Hong Kong to have a chance to affect the weather in New York. Because local variability is much less complex than global variability, less information is lost when only the ensemble variability is used. Greater computational efficiency means that the team can use larger ensembles.
To test their product, Kostelich says, "We had a bake-off." They compared their forecasts based on weather data from years before and compared the error of their forecasts with that of forecasts generated by the National Centers for Environmental Prediction, which are used by weather stations across the country. LETKF always did at least as well, but in areas with few weather stations, like in the middle of an ocean, the improvement was as much as 65%.
"In the southern hemisphere, where you have lots more water compared to land, that's where we are particularly good," Kostelich says. This explains the Brazilian government's interest in Kostelich's approach. In the northern hemisphere, by contrast, the technique does not lead to significant improvement.
Such comparisons are tricky, and there's no generally accepted method for them, says Ronald Errico of NASA's Goddard Earth Sciences and Technology Center. Brian Hunt, a member of the LETKF team, says that despite their test results, currently used methods still have an edge in most circumstances.
Still, LETKF has some major advantages, Hunt says. For one thing, it is much less computationally expensive than current methods. Furthermore, unlike current approaches, its implementation depends only on the selection of the grid points, not on the particular partial differential equations making up the model. That means that the model can be changed without changing data assimilation---an enormous saving. The same technique can be applied to very different models, like ocean models. One group is even applying it to models of the brain. Finally, as mentioned earlier, the ensemble approach is well suited to use on parallel computers.
"We're doing something that can be as accurate or at least nearly as accurate as other similar approaches," Hunt says, "but we can do things a lot more efficiently in terms of the computational power required and also in terms of the people time required."
Julie Rehmeyer writes about mathematics and science from Berkeley, California. She is the online math columnist for Science News.
![]()
