
Twenty-Plus Years of Netlib and NA-Net, Part II
May 15, 2006
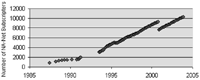
Figure 1. NA-Net subscriber growth.
Jack Dongarra, Gene Golub, Eric Grosse, Cleve Moler, and
Keith Moore
In the first part of this article (SIAM News, April 2006, page 1), the authors traced the development and impact of the mathematical software library Netlib. In this concluding part, they look at another innovative, related undertaking of the community: NA-Net, a collection of services designed to foster the exchange of information and a sense of community among numerical analysts.
By the time Netlib was established, Gene Golub, then chair of the Computer Science Department at Stanford University, had been maintaining an "na list"---e-mail addresses of numerical analysts---for several years. By 1983, this list was being used to provide an e-mail forwarding service. Also available was an e-mail broadcast facility that, by February 1987, had evolved into a moderated e-mail "digest," which soon became a weekly electronic newsletter. A "white pages" database and a Web interface were eventually added, resulting in the set of services provided by NA-Net today. NA-Net remains a widely used and valuable resource for the numerical analysis community. The NA Digest, one of the oldest electronic periodicals, continues to grow steadily in popularity.
In approximately 17 years as editor of the NA Digest, Cleve Moler, who stepped down last fall, saw the number of subscribers grow from a few hundred to more than 11,000. Moler is currently president-elect of SIAM.
Software and Hosting
At some point, from the list of e-mail addresses maintained by Gene Golub at Stanford, an e-mail system was configured so that mail to na.lastname@su-score (later, score.stanford.edu) would be forwarded to the person on the list with that last name. In the original implementation, entries from Golub's list were copied manually into a system alias file (requiring interaction by the system administrator each time the list was updated). Eventually, Mark Kent and Ray Tuminaro wrote software that allowed generation of the forwarding aliases and address list (for human perusal) from a common database [3].
One of the primary benefits of NA-Net's forwarding facility in those days was the uniform address for all subscribers. Before Internet access became ubiquitous, e-mail traveled over a hodgepodge of dissimilar networks, each with its own addressing scheme. The sender of a message between dissimilar networks often had to "source route" the message through a gateway by embedding the recipient's address inside the address of the gateway. Because each network had its own addressing convention, an address that reached a recipient from one location in the network would not necessarily work from another location. For mail to NA-Net subscribers, however, a sender needed to know only how to send mail to one na.lastname address; the same pattern would work for any NA-Net subscriber. This took out some of the guesswork of mailing between networks, at least in the case of NA-Net subscribers.
With the broadcast facility, a message to [email protected] would be forwarded to everyone on the list. Eventually, traffic volume and accidental misuse became significant enough that some sort of moderation was required for the broadcast facility, which was consequently converted to an e-mail "digest." A moderator would review messages sent to [email protected], and the selected messages would then be sent out to everyone. The first issue of the digest was issued on February 13, 1987. Appearing at first at irregular intervals, the digest soon settled into a weekly publication schedule.
In December 1990, NA-Net was moved to Oak Ridge National Laboratory, with new software written by Bill Rosener. The new software preserved the na.lastname forwarding and digest functions, but also allowed individuals to add themselves to NA-Net, remove themselves, or change their addresses--an improvement on previous versions, which required manual maintenance of the subscriber list. To subscribe, a user now sent an e-mail message to [email protected] with the following fields in the message body:
Firstname: user's first name
Lastname: user's last name
E-mail: user's e-mail address
The NA-Net server would reply with a message indicating whether the user had been successfully added. To unsubscribe, a user would send a similar message to [email protected]; to change an address, the message was sent to [email protected]. Each function had its own e-mail address and its own requirements for the format of the data to be supplied [2].
In May 1991 a "white pages" facility was added to NA-Net. Members could store information about themselves, such as their interests and home and work addresses, in the white pages database. This information would be made available in response to queries to [email protected].
By June 1993 the service had become so popular that the server was having difficulty handling the traffic. At this time Keith Moore rewrote the entire NA-Net software package to improve scalability (especially of e-mail distribution) and robustness, but the user interface did not change. This software remains in use today, with only minor changes. In November 1994, to eliminate the requirement that requests be submitted in text-based e-mail with rigidly defined syntax, a Web interface was added.
NA Digest: History and Content
Gene Golub was the original editor of the NA Digest. In July 1987, when Golub began a sabbatical leave from Stanford, Cleve Moler of The MathWorks took over as editor. With only occasional absences, he continued to edit the digest until September 2005. Tamara Kolda of Sandia National Laboratories is the current editor.
As the name suggests, the intent of the NA Digest has been to transmit short announcements summarizing more extensive material available elsewhere. Today, almost all digest contributions have URLs pointing to more complete announcements available on the Web.
The NA Digest has generally contained anything of interest to the numerical analysis and mathematical software community, including both technical discussions and information about members of the community. A typical issue contains conference and workshop announcements, advertisements for jobs, software release announcements, change-of-address announcements, new book announcements, journal contents, and notices about awards, significant achievements, and death of community members.
Reasonably complete archives of the NA Digest are available at http://www.Netlib.org/na-digest-html/. The archives contain a great deal of material of interest to anyone studying the history of numerical analysis software.

Tammy Kolda of Sandia National Labs in Livermore, California, was named editor of the NA Digest in the fall of 2005.
Usage Patterns
Based on early reports in the NA Digest and on log files maintained since 1993, the number of NA-Net subscribers has in-creased steadily, from 821 in May 1997 to the current total of 11,295 (Figure 1). (The discontinuity in 2000 was caused by the removal of many addresses that were no longer reachable, i.e., BITNET addresses.)
Several thousand messages per day are forwarded through NA-Net's e-mail forwarding service. A perusal of log file entries reveals that many appear to be spam. The NA Digest subscriber list was long made available for download over Netlib, a holdover from the days when the network was small and it could be assumed that most people with network access would act reasonably. Moreover, anyone could obtain the list, by sending mail to [email protected]. Even after the list was removed from Netlib and the sendlist address was disabled, subscriber addresses were occasionally found to have been leaked by various means.
Impact on the Community
The international numerical analysis community is small enough that it still has a cohesive, "family" feeling. We believe that the NA Digest has helped maintain that feeling. The fact that it is still in low-tech, simple text e-mail format means that it is accessible to anyone who has access to a computer and a network connection. This is particularly important to subscribers around the world who are unable to travel to meetings. Moler recalls meeting people on several occasions who recognized him primarily as the "guy who sends me e-mail every week."
Related Projects
Xnetlib. Created in 1990, predating the Web and tools like Netscape, Xnetlib was a tool for "Web-based" software distribution. Whereas Netlib originally used e-mail as the user interface to the collection of public-domain mathematical software, Xnetlib used an X-Window interface and socket-based communication. Users would download and install the X-Window interface on their systems, as with Netscape, although Xnetlib could connect only to the Netlib server. Xnetlib made it easy to search a large distributed collection of software and to retrieve requested software in seconds. The last release of Xnetlib was version 1.3. Web browsers now make available most of the capabilities once provided by Xnetlib.
NHSE. In operation from 1994 to 2004, the NHSE (National HPCC Software Exchange) was a distributed collection of software, documents, data, and information of interest to the high-performance and parallel computing community. Evidence of the significance of this collaborative effort can be found in the many useful reports and tools generated, as well as in the many repositories that were, and continue to be, created with the Repository in a Box tool-kit developed in 1996.
Continued operation of the site without funding was impractical, however, and the site has been taken down. The NHSE meta-repository, which consists of metadata describing software applications and tools from the PTLib, HPC-Netlib, and BenchWeb repositories combined, is still available. Because PTLib and HPC-Netlib are no longer maintained, however, the metadata from those repositories are frozen in time. Only the BenchWeb content is still maintained.
RIB. Repository in a Box provides a toolkit for building and maintaining metadata repositories. Developed by the NHSE Technical Team at the University of Tennessee, Knoxville, RIB initially provided tools exclusively for the creation of software repositories. The recently released RIB 2.0 makes it possible to create general metadata repositories. The creation of software metadata repositories remains the primary application of RIB [1].
RIB has two primary design goals: promotion of software reuse and interoperability. RIB promotes software reuse by providing tools for the construction of metadata repositories. These repositories contain information pertaining to software packages and routines, along with abstracts, licensing information, point of contact, and so forth. They are intended to be discipline-oriented and to act as central access points for software information.
The interoperability features of RIB allow repositories to share information in a scalable and efficient manner. Additionally, these features allow domain-specific repositories to be gathered into larger repositories with a common access point. NHSE, for example, is an aggregation of several other repositories, with NHSE providing a common access point--so far as the user is concerned, all the data is contained within NHSE.
NetBuild. NetBuild is a tool that automates the process of selecting, locating, downloading, configuring, and installing computational software libraries via the Internet. Additional tools aid in the construction and cataloguing of libraries in the format used by NetBuild.
NetBuild is easy to use: Users simply type "nb," followed by whatever command they would use to compile or link their programs. NetBuild works by invoking users' commands in an environment that intercepts calls to compilers and linkers. On intercepting those calls, NetBuild identifies and downloads any libraries that are needed, and passes the filenames of the downloaded libraries to the real compilers and linkers. Unlike many other tools, NetBuild is designed to work across a wide variety of computing platforms. In order to support high-performance computing applications, NetBuild can also perform fine-grained matching of libraries and target platform characteristics to select the version of a library that will provide the best performance for a given target platform [4].
Conclusions
Software distributed by Netlib is accompanied by a disclaimer: "Anything free comes with no guarantee." In contrast to commercial vendors like NAG and IMSL, Netlib offers no support beyond whatever documentation contributing authors choose to provide with their codes. On the other hand, Netlib provides free, easy access to a large body of high-quality code, and its phenomenal growth attests to the value of this service. We hope that Netlib, by making high-quality code even more accessible, will encourage software developers to make their source codes freely available and will make good programming easier for the scientific computing community.
For more than two decades, these characteristics have made Netlib a pivotal asset for the computational science community. The experience gained from Netlib has been transferred to a number of other projects designed to promote software-collection management and software reuse. The National High Performance Software Exchange strove to apply the techniques and technologies of Netlib to more loosely coupled software repositories. NHSE also attempted (successfully) to make the creation and maintenance of software repositories easier through the Repository in a Box toolkit.
By making high-quality numerical software and interchange readily available to application scientists, Netlib and the NA Digest have provided a singular resource for the advancement of science and education. It is well known that the use of high-quality software libraries can speed the development of new software applications. By making these libraries available to the science and engineering communities, Netlib has helped make possible a faster pace of innovation and investigation.
Additionally, Netlib-provided services like NA-Net give members of these communities a forum for discussion and a means of maintaining contact with their peers. NA-Net in particular has also facilitated the cross-pollination of ideas and techniques among scientists, engineers, and numerical analysts.
The idea that computational modeling and simulation represent a new branch of scientific methodology, alongside theory and experimentation, was introduced about two decades ago. It has since come to symbolize the enthusiasm and sense of importance that people in our community feel for the work they are doing. But when we try to assess how much progress we have made and where things stand along the developmental path for this new "third pillar of science," we can gain perspective by looking back at the development of the other pillars. It seems clear that while computational science has had many remarkable youthful successes, it is still at a very early stage in its growth.
Many of us who want to hasten that growth today believe that the most progressive steps in that direction require much more community focus and expenditure on the vital core of computational science: software and the mathematical models and algorithms it encodes. When it comes to advancing the cause of computational modeling and simulation as a new part of the scientific method, there is no doubt that the required complex software "ecosystem" must take a place at center stage.
At the application level, the science has to be captured in mathematical models, which are expressed algorithmically and, ultimately, encoded as software. Accordingly, the majority of the funding for a typical project supports this translation process, which starts with scientific ideas and ends with executable software, and which over its course requires intimate collaboration among domain scientists, computer scientists, and applied mathematicians. This process also relies on a large infrastructure of mathematical libraries, protocols, and system software that has taken years to build up and that must be maintained, ported, and enhanced for many years to come if the value of the application codes that depend on it are to be preserved and extended. The software that encapsulates all this time, energy, and thought routinely outlasts (usually by years, sometimes by decades) the hardware it was originally designed to run on, as well as the individuals who designed and developed it.
The life of computational science thus revolves around a multifaceted software ecosystem. But today there is (and should be) a real concern that the ecosystem of computational science, with all its complexities, is not ready for the major challenges that will soon confront the field. Domain scientists now want to create much larger, multi-dimensional applications in which a variety of previously independent models are coupled, or even fully integrated. They hope to be able to run these applications on petascale systems with tens of thousands of processors, to extract all the performance that these platforms can deliver, to recover automatically from the processor failures that occur regularly at this scale, and to do all this without sacrificing good programmability. This vision of what computational science wants to become contains numerous unsolved and exciting problems for the software research community. Unfortunately, it also highlights aspects of the current software environment that are immature, underfunded, or both.
Advancing to the next stage of growth for computational simulation and modeling will require that as we solve basic research problems in computer science and applied mathematics, we work at the same time to create and promulgate a new paradigm for the development of scientific software. Netlib and the NA Digest, for the most part, have been the results of volunteer efforts. Given the importance and success of these services, some obvious questions arise: How should activity of this kind be supported? Where should it be done? At universities? At companies like The MathWorks? We've been told many times by funding agencies that "it isn't research." These are hard, but important, questions that need to be answered as we move forward. Progress on these fronts will require sustained funding from governmental sources to promote efforts like Netlib that have proved to be so fundamental to scientific research.
Acknowledgments
The authors thank Don Fike for assistance with Netlib statistics, Mark Crispin and Mark Kent for information about early NA-Net implementation, and Mel Ciment, who was at the National Science Foundation and provided seed funding for Netlib and NA-Net when they first started.
References
[1] S. Browne, P. McMahan, and S. Wells, Repository in a Box Toolkit for Software and Resource Sharing, CS Tech. Rep. UT�CS�99�424, University of Tennessee, Knoxville, 1999; http://www.nhse.org/RIB/pubs/ut-cs-99-424.ps.gz.
[2] J. Dongarra and W. Rosener, NA-Net/Numerical Analysis Net, Tech. Rep. ORNL/TM�11986, Oak Ridge National Laboratory, December 1991.
[3] M. Kent, The Numerical Analysis Net (NA-NET), Tech. Rep. 85, Institut f�r Informatik, Eidgen�ssische Technische Hochschule Z�rich, January 1988.
[4] K. Moore and J. Dongarra, NetBuild (version 0.02), CS Tech. Rep. UT�CS�
01�461, University of Tennessee, Knoxville, March 2001; http://www.cs.utk.edu/~library/TechReports/2001/ut-cs-01-461.ps.Z.
Jack Dongarra is a University Distinguished Professor in the Department of Computer Science and director of the Innovative Computing Laboratory and the Center for Information Technology Research at the University of Tennessee, in Knoxville; he is also a distinguished member of the research staff and Mathematics Division at Oak Ridge National Laboratory. Gene Golub is the Fletcher Jones Professor of Computer Science at Stanford University. Eric Grosse is a member of the research staff at Bell Laboratories, Lucent Technologies. Cleve Moler, SIAM's president-elect, is the chief scientist and founder of The MathWorks. Keith Moore is a member of the research staff at the Innovative Computer Laboratory at UTK.
![]()
